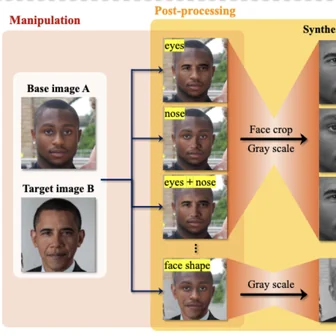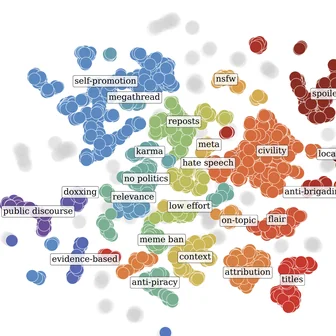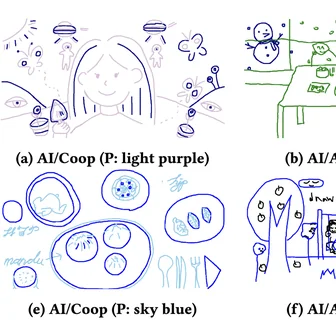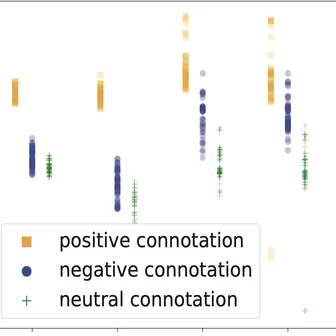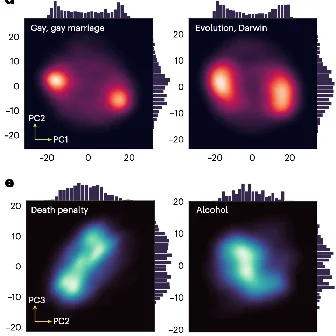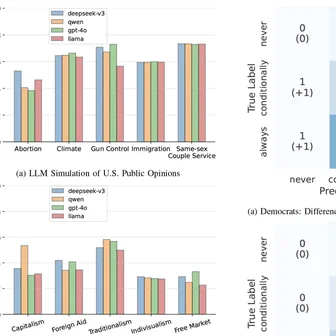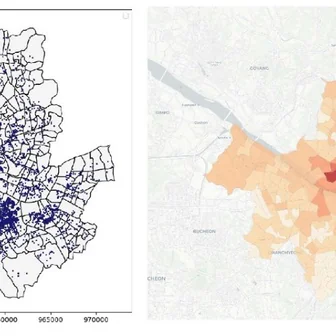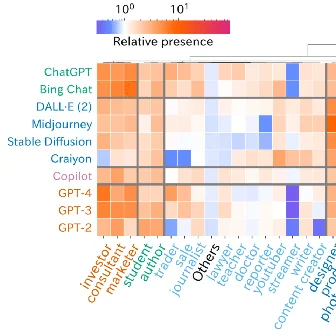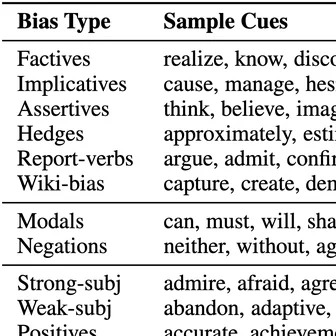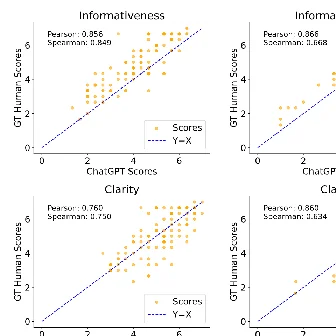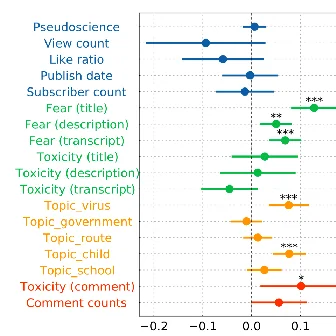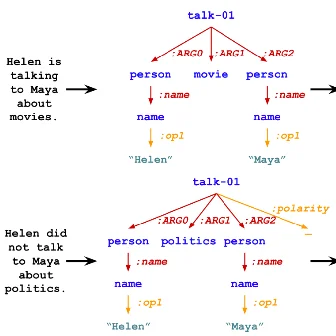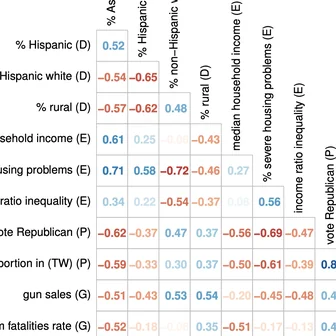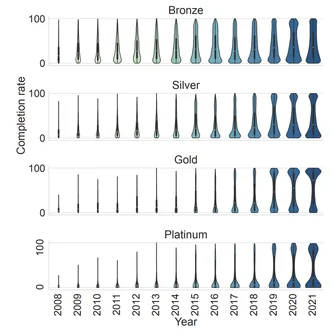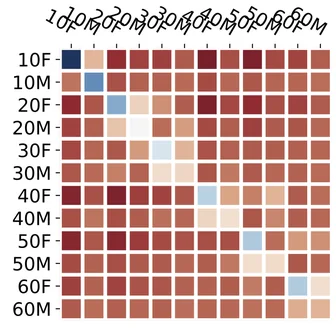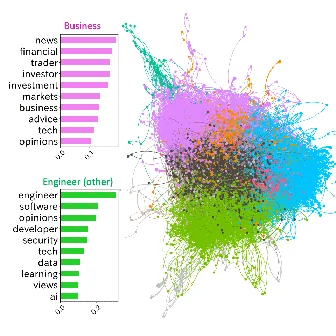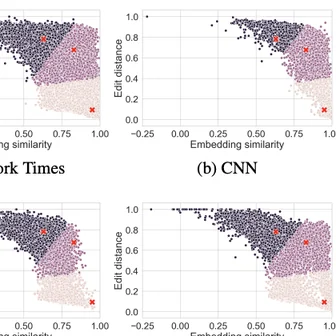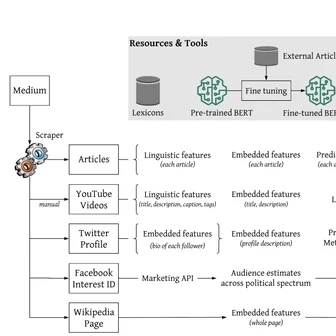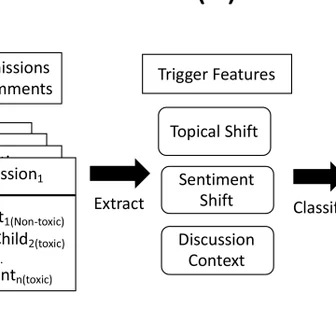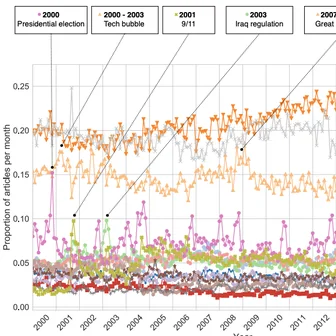
Byunghwee Lee, Sangyeon Kim, Filippo Menczer, Yong-Yeol Ahn, Haewoon Kwak, Jisun An
arXiv preprint arXiv:2603.11253, 2026 · 2026 · 4 cites
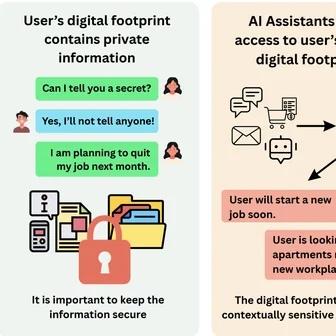
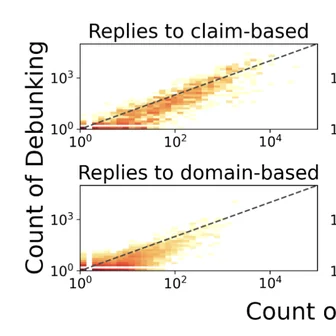
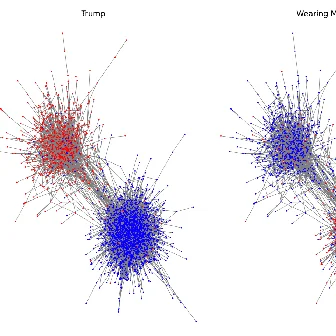
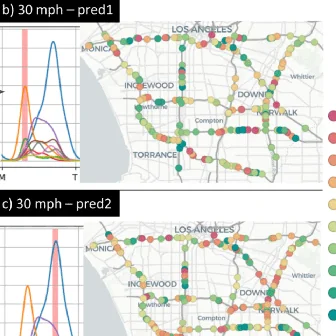
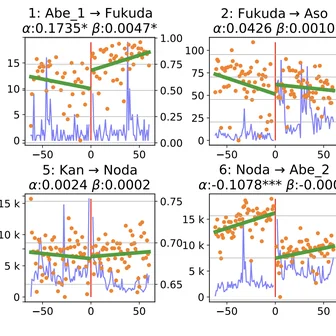
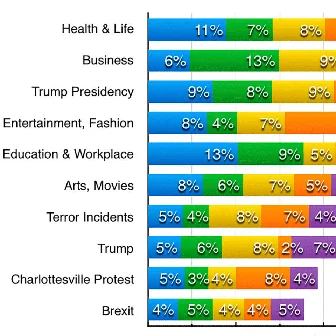
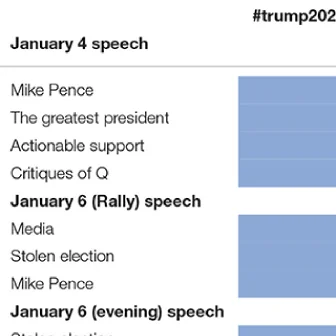
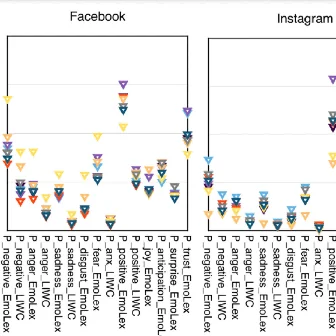
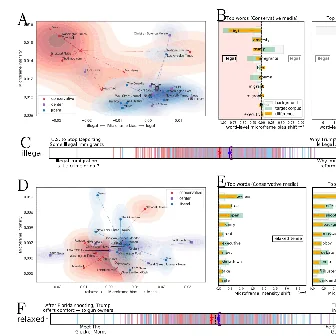
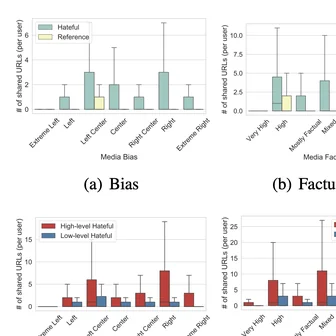
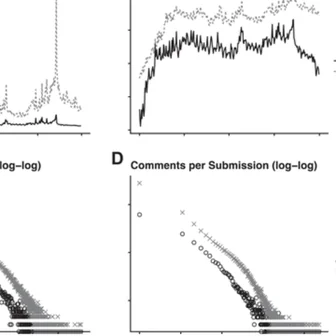
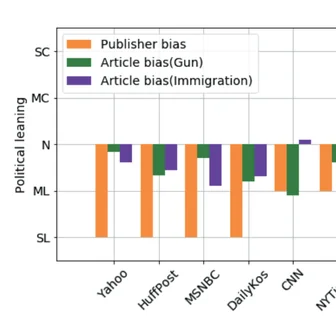
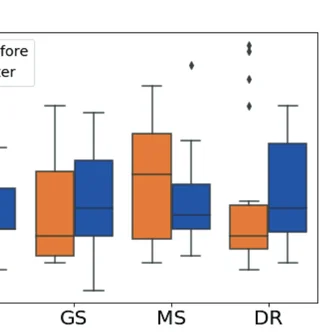
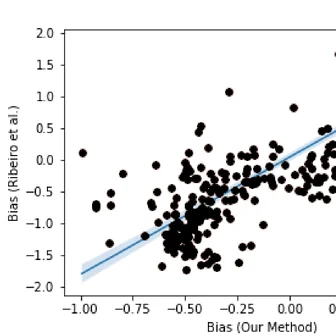
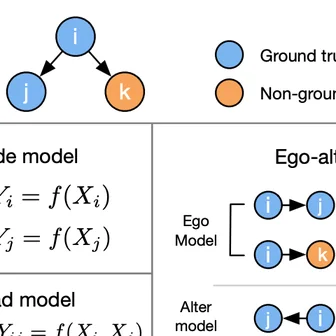
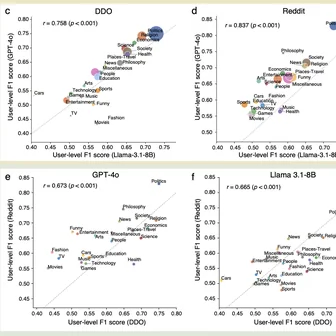
Innocuous online preferences (the bands you follow, the slang you use) can reveal sensitive traits. We show that LLMs reliably infer hidden political alignment from DebateOrg and Reddit conversations, outperforming traditional ML. Accuracy improves further when text-level inferences aggregate to the user level and when we use politics-adjacent domains, underscoring a serious privacy risk.